
개발새발
GPU 본문
GPU의 역사
- 3D Accelerator: 초기의 GPU는 3D 이미지를 빠르게 렌더링하기 위해 등장한 3D 가속기로, 주로 특정 그래픽 작업을 가속하는 데 사용되었다.
- Programmable Shader Architecture: 이후 GPU 아키텍처는 프로그래머블 셰이더를 도입하여, 그래픽 파이프라인의 각 단계를 프로그래밍할 수 있게 되었고, 맞춤형 그래픽 효과를 구현할 수 있게 되었다.
- General Purpose Computing on GPUs: 현재의 GPU는 단순히 그래픽 처리만이 아니라 다양한 분야에서 병렬 연산을 수행하는 강력한 도구로 자리잡고 있다.
Graphics Pipeline
그래픽 파이프라인은 3D 데이터를 2D 이미지로 변환하는 일련의 과정이다.
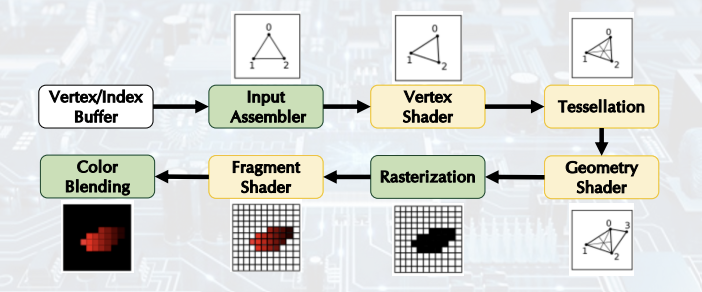
- Rasterization: 3D 객체를 2D 이미지로 변환하며, 객체의 거리와 위치에 따라 크기를 조절하여 시각적 깊이를 표현한다.
- Fragment Shader: 각 픽셀의 색상과 질감을 조정하며, 조명 및 그림자와 같은 효과를 처리한다.
- Color Blending: 투명도와 색상 혼합을 조정하여, 겹치는 객체가 자연스럽게 보이도록 한다.

GPU 아키텍처
- SM(Streaming Multiprocessors): GPU는 여러 개의 SM으로 구성되며, 각 SM은 수천 개의 스레드를 병렬로 실행할 수 있다. CPU는 주로 순차 처리에 특화되어 있는 반면, GPU는 대규모 병렬 처리에 최적화되어 있다.
- Primitive Distributor: 작업을 각 SM으로 분배하는 스케줄러 역할을 한다.
- Crossbar: GPU 내부에서 빠른 데이터 전송을 지원하는 대형 네트워크이다.
- Vertex Shader: 3D 공간에서 객체의 정점 위치를 계산한다. 게임 개발 시, 다양한 좌표계를 활용하여 객체를 다루게 된다.
- Local Space: 객체의 고유 좌표.
- World Space: 객체가 전체 환경 내에서 위치하는 좌표.
- View Space: 2D로 보는 카메라 시점을 설정하는 좌표.
- Clip Space: 화면에 표시될 수 있는 범위 내의 좌표. 범위를 벗어나면 클리핑된다.
- Tessellation and Geometry Shader: 물체가 폭발하는 등의 복잡한 이펙트를 줄 때 사용된다.
- Rasterization: 이미지를 기준으로 몇 개의 픽셀로 구성해야 하는지 결정한다.
- Fragment Shader: 픽셀의 색상을 결정한다.
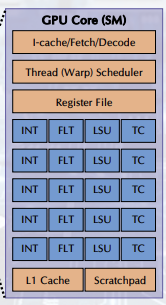
int-int 연산기
flt-float 연산기
load store unit-
tc-tensorcore-ai 연산기
GPGPU 개념
- Ray Tracing: 현실적인 조명 계산을 통해 이미지를 리얼하게 구현하는 방법이다. 이는 광원의 물리적 특성을 기반으로 장면을 더욱 사실적으로 표현한다.
- OpenCL은 다양한 컴퓨팅 시스템(CPU, GPU, FPGA 및 기타 프로세서)의 크로스 플랫폼 병렬 프로그래밍을 위한 개방형 표준이다 CUDA와 유사
- CUDA: CUDA는 CPU와 GPU 간의 협업을 통해 GPU에서 병렬 처리를 수행할 수 있도록 해준다. 일반적인 CPU 코드와 유사하게 작성된 코드를 NVCC 컴파일러로 GPU에서 동작하는 CUDA object file로 컴파일해준다.
- GPU는 데이터 의존성이 없는 병렬 연산에 매우 강력한 성능을 발휘한다.
GPU-이미지 생성 API
GPGPU- output이 image가 아니라 data 형태이다, 어떻게 하면 GPU를 활용해서 General-purpose연산을 할지
GPGPU는 그래픽 처리 장치(GPU)를 사용하여 계산을 수행하는 것이다. 원래는 전통적으로 중앙 처리 장치(CPU)에서 처리하는 일.
GPU와 CPU의 협업
GPU는 독립적으로 작업을 수행할 수 없다. CPU가 명령을 내려줘야 GPU가 작업을 수행할 수 있다.
- CPU가 데이터를 준비한 후, 이를 GPU로 전달한다.
- 연산을 수행하고, 그 결과는 GPU 메모리에 저장된다.
- GPU 메모리에서 결과를 CPU로 가져와 확인한다.
- Host: CPU
- Device: GPU
- Kernel: 하나의 함수가 커널로 불리며, 이 함수는 GPU에서 병렬로 실행된다.
Parallel Programming & Vector Addition
- CUDA에서 각각의 스레드는 고유한 ID를 가지고 있으며, 각 스레드가 독립적으로 계산을 수행한다.

함수를 호출하기 전에 항상 GPU에 데이터를 넣어줘야 한다!!
Parallel Programming & Vector Addition

각각의 쓰레드는 본인 고유의 ID를 가지고 있고, 각각 계산된다.
Function Declaration
__가 붙어 있으면 GPU 에서 동작해야하는 코드이다
함수 지정자:
- __host__: CPU에서 실행되는 함수를 지정.
- __global__: 호스트에서 호출되며, GPU에서 병렬로 실행되는 커널 함수를 정의.
- __device__: GPU에서 실행되며, 다른 GPU 함수에서만 호출될 수 있음.
Setting the Number of Threads in CUDA Kernels
몇개의 스레드를 만들고 몇개의 스레드를 사용할지 결정해야힌다. 스레드 블락, grid를 통해 몇개의 스레드를 쓸지 결정-하드웨어
- GPU는 스레드로 작업을 처리하며, 스레드는 블록과 그리드로 구성됨.
- 그리드(Grid): 여러 블록의 집합.
- 블록(Block): 여러 스레드의 집합으로, 각각의 블록은 SM에서 처리됨.
cudaMalloc-GPU에서 쓸 메모를 할당
const int MAX_SIZE=1024;
int main(){
…
float *d_a, *d_b, *d_c;
int arraySize = MAX_SIZE * sizeof(float);
cudaError_t err = cudaMalloc((void **) &d_a, arraySize);
checkCudaError(err);
err = cudaMalloc((void **) &d_b, arraySize);
checkCudaError(err);
err = cudaMalloc((void **) &d_c, arraySize);
checkCudaError(err);
…
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);arraySize-할당 받은 배열 크기
const int MAX_SIZE=1024;
int main(){
…
err = cudaMemcpy(d_a, inputA, arraySize, cudaMemcpyHostToDevice);
checkCudaError(err);
err = cudaMemcpy(d_b, inputB, arraySize, cudaMemcpyHostToDevice);
checkCudaError(err);
…
CPU에서 GPU로 데이터 전달
글로벌 메모리 (Global Memory):
- 개념적으로 호스트 메모리와 유사하며, 오프칩 메모리
- 모든 스레드가 접근 가능
- 가장 높은 접근 지연 시간을 가지므로 성능 병목이 될 수 있음
레지스터 (Register):
- 가장 빠른 온칩 메모리
- 많은 스레드를 관리하기 위해 대형 레지스터가 존재
공유 메모리 (Shared Memory):
- 프로그래머가 선택적으로 사용할 수 있는 낮은 지연 시간을 제공하는 프로그래머블 메모리
- 동일한 스레드 블록 내의 모든 스레드가 공유함
상수 메모리 (Constant Memory):
- 크기가 작은 읽기 전용 메모리
- 읽기 전용으로 사용되고, 기록되지 않는 데이터를 저장하는 데 사용됨
'임베디드시스템' 카테고리의 다른 글
| Image Blur (GPU) (0) | 2024.10.23 |
|---|---|
| Image Blur(CPU) (6) | 2024.10.17 |
| CUDA (0) | 2024.09.26 |
| Professor (0) | 2024.09.25 |
| Linux (4) | 2024.09.11 |
'임베디드시스템' Related Articles
more

